Introduction
I took this project as an example for writing a field report because to me it seems a somewhat typical situation: you want to bring MPS into a project, but:
- in a brownfield project, all stuff is done without MPS until now
- things are not so easy importable
- team members don’t know MPS and/or refuse to use it
- and more constraints exist that don’t let you write your production code with MPS
So is it even possible to use MPS when only here and there has something to be changed? This was the question I was interested in, and the only way to find it out was trying it. The situation was as follows.
An existing EAI brownfield project had to be extended by another integration use case. The integration is done by an integrations server which has to be configured by a proprietary tool. So it was no option to create the ‘productive code’ by MPS, but there were enough tasks left:
- the requirements were mostly unknown and expected to pop up every now and then, so they have to be analyzed and managed
- acceptance and regression tests have to be created
- of course, best would be to combine these two having an executable specification
- for localization, the property files for every language have to be managed
- PDF creation is done by Apache FOP, so some support for creating the fo-file would be nice
Until then, we used Scala for acceptance/regression/integration tests.
Choosing a language for executable specification
For formal requirements analysis and management, we have three languages in our repository:
- the Use Case form
- the SOPHIST form
- gherkin
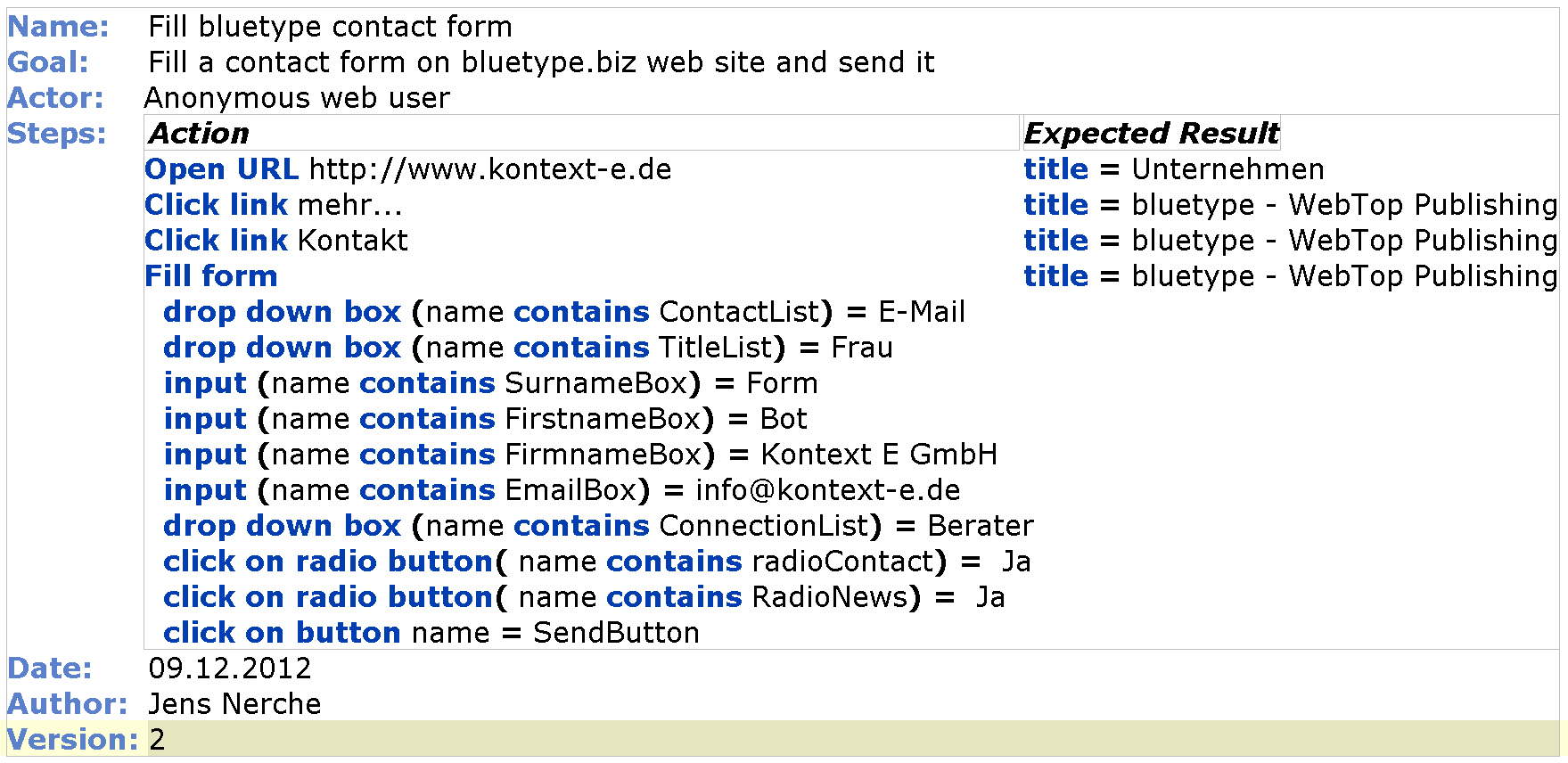
The Use Case form looks like this:

This is our form to gather details for this what is shown in UML use case diagrams as overview. Here are only the mandatory fields, there are lots of optional fields. In an office document it would be a simple table, but in MPS it is translated into Java code and can be executed.
The SOPHIST form is created by the SOPHIST folks and published in various articles and books. In MPS we have currently no translation to Java code and no interpreter, so it is not executable.
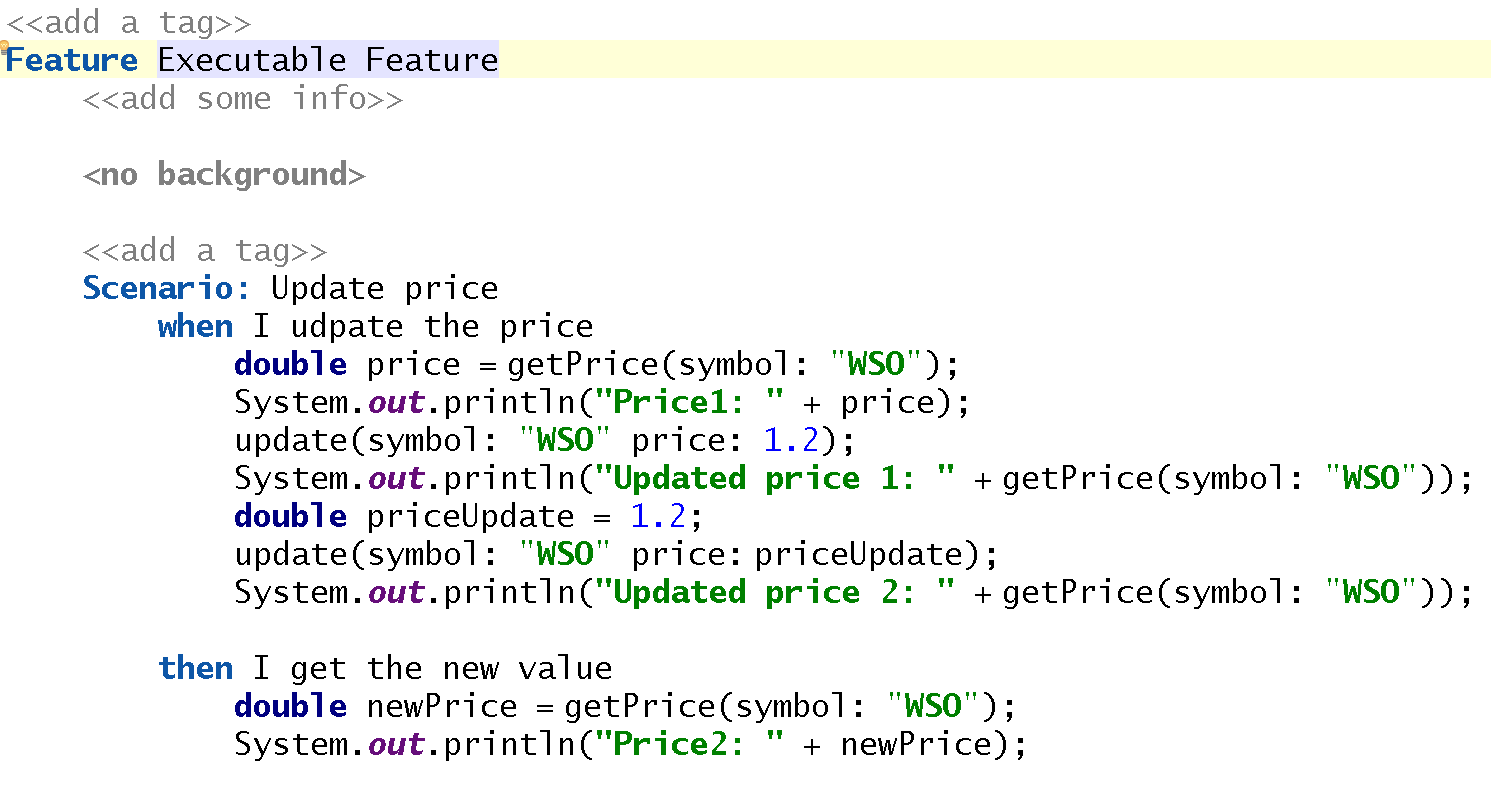
Gherkin in contrast is executable and looks like this:

You can see some properties of the implementation in MPS:
- features and scenarios may have tags to filter them
- scenarios may be marked as pending so that they are not executed
- some checks exist and report errors to the scenarios
- steps may be marked as ‘open point’ and were highlighted by the orange background
The meta data of the use case form like author, date, and version is not needed. Also in this integration case there are no actors. And there are lots of examples for input, so the gherkin implementation was chosen.
With gherkin, we have two flavors. The first was shown above, the second is more flexible and has the implementation next to the scenario step:

Indeed the Java implementations details are hidable, it stays a mixture of two abstraction levels which is not so good. Nevertheless this form is very suitable if there is much experimentation with implementation is needed. And this language could be enhance by a refactoring which creates a language concept and a generator reduction rule for the detail part (maybe named ‘extract concept’ or so, we still have to think about it).
Because in this case the flexibility was not needed and the first gherkin form offers more comfort for creating scenarios, it was chosen.
Including XML
As stated above, there was plenty of examples for input. Looking at them more closely it turned out that only two or three cases were covered by nearly all examples and most cases had no examples. So we had to create the remaining cases ourself. The examples came as XML files, so we extended the XML language delivered with MPS by some little things. The most visible one is an accentuation of what is special about this example:

On an element or attribute, you can attach a reference to the scenario where the description relevant to the highlighted part is. Because large parts of all XML examples are identical and sometimes only one attribute differs, the interesting thing is much easier to find. Not existing yet but very easy to do now is an overview of all XML modifications so that it is easier to find out if all cases are covered or something is missing.
As helpers an XML file importer, an exporter from MPS editor to org.w3c.dom.Document and an XSLT transformer which takes the XML and stylesheet from MPS editors and puts the result also into an MPS editor were created.
Extending Gherkin
Gherkin is a language in the general domain of ATDD/BDD. For the business domain of the project, we extended gherkin.
One extension point of gherkin is the clause of given, when, then, and the others. The original plain text clause may be replaced by other clauses. We defined all for the narrow domain. So while creating or editing a clause, the typical Ctrl-Space-suggestions work. We defined reduction rules for them so that the generator produces the test code.
The test code often references elements and attributes in the XML examples. We added element and attribute references for the g-w-t-clauses. In the specification the data is directly visible, and in the test code can the correct data placed in assert statements. Once we noticed that there is a 1:1 relationship between scenarios and XML examples, the element and attribute reference suggestions could be much more narrow.
Another extension point of the gherkin language is the progress for scenarios. A scenario can be in states like ‘pending’ or ‘done’. We defined project specific states with project specific color codes. That makes it easy to stay up to date with the project progress.
Also another extension point is useful for that: statistics. We defined some to get the numbers of total scenario count, count of pending scenarios and so on.
Although the FeatureSet concept was extended to an ExecutableFeatureSet, for legacy brownfield reasons we generated the Java test code and XML files from our models and executed the tests in an external environment. This also has the benefit that the regression tests can run without MPS.
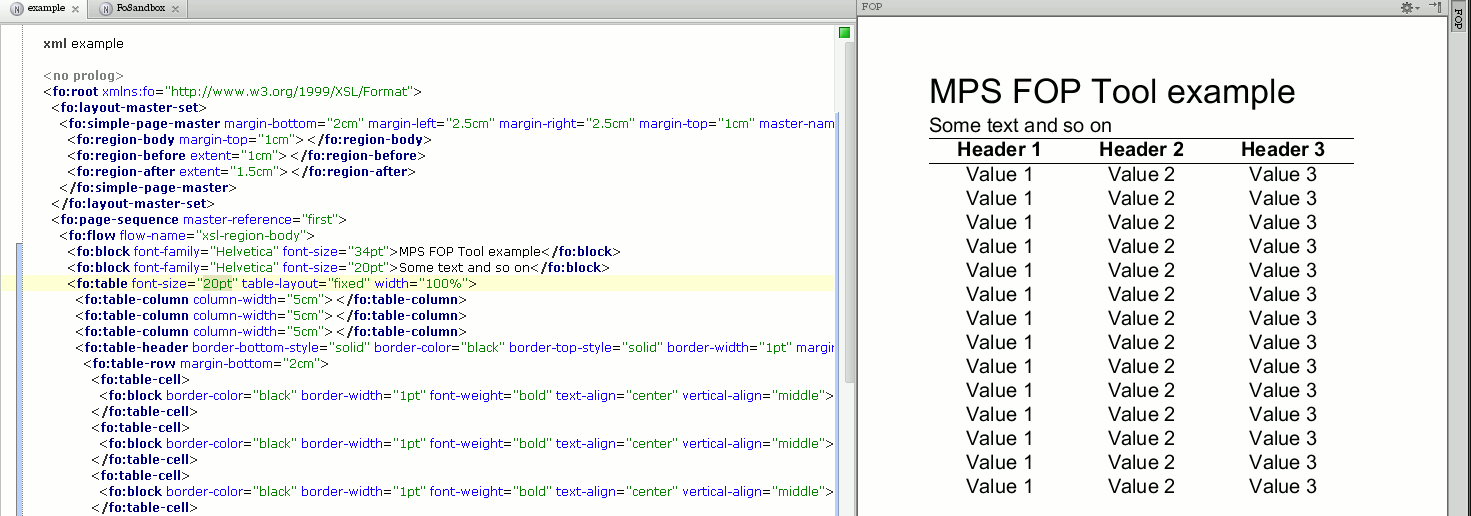
The FOP Tool
One requirement was to create PDF from input XML. To create a template, the first attempt was a roundtrip like this:
- do some modifications on the FO file
- close the previously opened PDF (relevant on Windows)
- transform FO to PDF
- open the new PDF
- go to 1
This was slow and annoying. But Apache FOP is Open Source. Thus we could create a tool (aka view) that makes template work much more pleasant. In a view it shows the rendered picture of the current editor. The FO processing and picture rendering is done in a separate thread so that the editing is as fluent as without the preview.

Becoming international
Then the requirement to localize the PDF and other things emerged. Technically no big thing except the pain of maintaining the language property files, keeping them complete and without duplicate keys, having the translations not too long to fit into the boxes and so on. Not so painful with MPS. Only a tiny language is needed. In out case it has a custom persistence to store and load the solutions as CSV files. A domain expert is able to create more language property files using office tools she knows and doesn’t need MPS just for this case. Some checks and quick fixes take care of keeping all translations clean. And having the language property files as first-class citizens in the project allows a much better integration (referencing, find usages, warn about unused tokens,…).
Not done yet but very easy to do would be to create an ‘L10N’ application based in MPS with only the L10N solution included. So the domain expert could edit the translations while benefiting directly from the checks and quick fixes.
Conclusion
At the end, the team is still convinced that the decision for MPS was a good one. It is easy – even for not technical staff – to create and maintain executable test scenarios. They are much more readable than other kinds of executable specs. Not to mention that the tailored editor is unmatched by alternatives for programming Scala or Java BDD tests.
The effort of building or extending the languages was not as much as suspected. Especially if you take into account that L10N, FOP, and the XML tools are independent languages and easily reusable.
It was shown that even in a brownfield project and where the main code is not accessible by MPS the usage of this language workbench was worth it.